

Alors que l'A/B testing se démocratise, son efficacité réelle est souvent remise en question. Ces doutes sont-ils fondés ? Comment faire pour éviter de faire des erreurs avec un outil qui demande des compétences techniques non négligeables ? Voici quelques éléments de réponse.
Récemment, au coeur de l'écosystème Marketing, la lecture de plusieurs articles provoque la remise en cause de la valeur de l’A/B testing.
"I Spent All Summer Running A/B Tests, and What I Learned Made Me Question the Whole Idea http://t.co/IYSX6SjrSG "
— GrowthHackers (@GrowthHackers) 25 Octobre 2014
"Most Winning A/B Test Results Are Illusory" - http://t.co/pUzuynU0jO (PDF) (good but misses some points) pic.twitter.com/07tMELSu1D
— Craig Sullivan (@OptimiseOrDie) 26 Février 2014
Simple vague de jalousie devant le succès insolent de ces marques qui sont en train de devenir des incontournables ? Pas tout à fait. En fait, c’est une impression totalement fondée, puisque c’est un sujet qui revient assez souvent sur la table, principalement parce que le problème ne disparaît pas.
Il faut avouer qu’avec des rapports intitulés « La plupart des gains en A/B testing sont illusoires », ou des articles titrés « Comment je me suis (presque) fait virer à cause d’Optimizely », on peut se poser des questions. Le sujet a donné lieu sur Hacker News à un bref échange, entre le PDG d'Optimizely (une des solutions d’A/B testing les plus plébiscitées) et un membre du forum.
Pourquoi on peut légitimement se poser des questions
Il y a plusieurs détails assez troublants et qui, sans aller jusqu’à la théorie du complot, exigent des réponses sérieuses. Le problème principal est le suivant : certains revendeurs de solution A/B testing semblent encourager les utilisateurs à arrêter leurs tests trop tôt.
Et contrairement à ce que disent beaucoup de fans de l’A/B testing sur ce sujet, il y a bien une chose qui est pire que de ne pas faire de tests : c’est de mal faire des tests. Ne pas faire de test peut priver de certains gains potentiels. Mal faire des tests peut faire croire à tort que les performances du site sont améliorées, alors que c'est exactement l'inverse qui est en train de se produire.
Et justement, arrêter un test trop tôt, c’est indubitablement mal faire un test. Alors, pourquoi cette erreur est-elle aussi récurrente ? La base de l’A/B testing c’est la signification statistique. Pour atteindre un seuil satisfaisant, il faut en général attendre que l’échantillon testé soit assez grand.
Le mot clé ici, c’est en général. En fait, il est tout à fait possible, et même courant, qu’un test franchisse le seuil de signification statistique sans pour autant que l’échantillon soit grand. La chance peut faire qu’une variante en cours de test, connaisse une série de succès nombreux sur un court laps de temps, par exemple.
Et là, l’erreur que font beaucoup (trop) de testeurs, c’est de croire que la signification statistique est une condition suffisante à l’arrêt d’un test... alors que ce n’est absolument pas son rôle ! En réalité, savoir si un test est statistiquement significatif pendant qu’il tourne n’a aucun intérêt.
Ce n’est qu’une fois que le test d'un échantillon est suffisamment grand qu'il est alors possible jeter un oeil à cet indicateur pour savoir si votre test est concluant ou non. Mais si cette erreur est commise si souvent, c’est aussi par la faute des vendeurs de logiciels d’A/B testing :
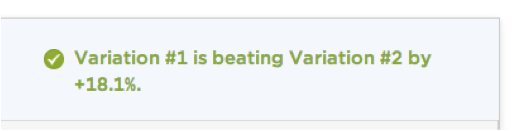
Avec un message dans ce genre, comment s'étonner que les utilisateurs mettent fin à leurs tests trop tôt ? Idem pour les écrans qui représentent l’évolution du taux de conversation dans le temps.
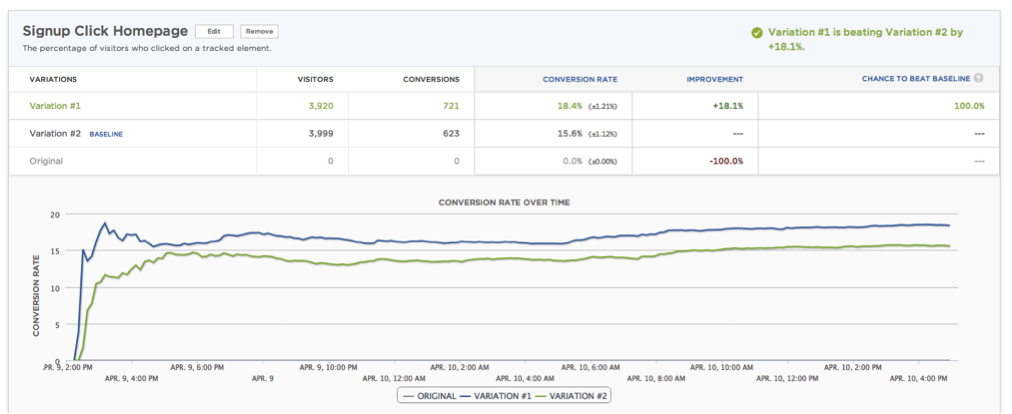
You can’t “spot a trend”, that’s total bullshit. — Peep Laja, créateur de ConversionXL et un des plus grands experts mondiaux de l’optimisation des conversions
En d'autres termes, c’est impossible de dire en un coup d’oeil si un test est gagnant ou non en regardant ce genre de courbe. D’un point de vue méthodologique, c’est une catastrophe. Le résultat du test n’a plus aucun sens, et les décisions qui vont se fonder dessus peuvent mener à des conséquences plus que dommageables, puisqu'il est alors tout à fait possible d'arrêter un test jugé «gagnant» qui va en réalité faire perdre de l'argent.
5 étapes pour ne pas se faire piéger
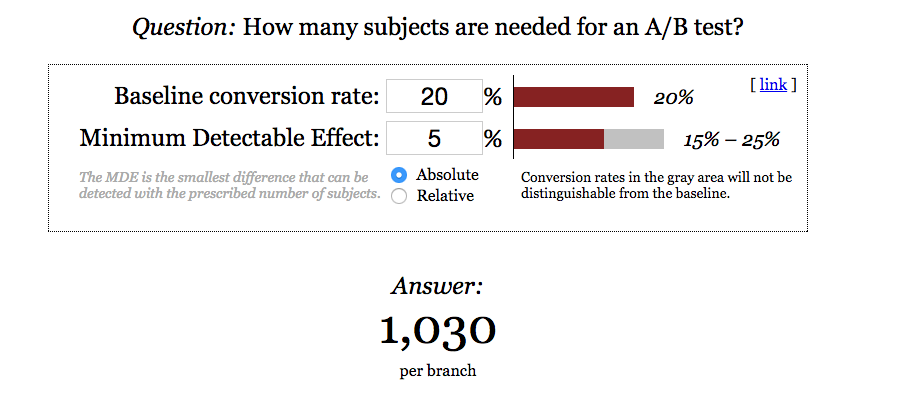
Bonne nouvelle : Pas besoin d’avoir un doctorat en statistiques pour faire un test A/B correctement. Il suffit d'utiliser quelques outils très simples et de suivre scrupuleusement les étapes suivantes.
La procédure à suivre est simple :
- Décidez d’un seuil minimum d’amélioration à partir duquel faire un test a un intérêt. Si vous améliorez un taux de conversion de 1 %, mais que cette amélioration vous rapporte moins que le coût du test (prix du logiciel, ressources humaines, etc.), ça n’a pas d’intérêt. Notez que plus vous voulez détecter un petit effet, plus le test prendra de temps.
- Utilisez ce seuil pour calculer la taille minimum de l’échantillon dont vous avez besoin. Utilisez un site comme celui d’Evan Miller, entrez votre taux de conversion actuel et l’amélioration attendue. (Vous ne devriez pas avoir besoin de changer les valeurs de signification et de puissance statistique usuelles).
- Lancez votre test, et attendez d’atteindre la taille d’échantillon que vous venez de calculer. Vous n’avez rien d’autre à faire. En fait, je vous recommande même de ne plus regarder le test du tout. Faites comme si c'était une boite noire qui ne s’ouvre qu’une fois la taille critique atteinte.
- Une fois l’échantillon testé, vérifiez si le résultat est significatif. Vous pouvez utiliser cet autre outil pour vous en assurer.
- Si le résultat est significatif, vous tenez une variation gagnante. Sinon, passez au test suivant.
Même si mener un test rigoureux peut parfois être plus complexe que ça (il faut aussi faire attention aux sources du trafic, à la durée de la période du test, etc.), appliquer cette méthode est un moyen sûr de ne pas commettre des grosses bourdes coûteuses. C'est le B.A.-BA.
Un repositionnement à venir pour les fournisseurs d'outils d'A/B testing ?
Là où tout ça est un peu ironique, c’est que'il est possible d'en apprendre autant (avec moult détails techniques en prime) en lisant un article très bien fait directement sur le site... d’Optimizely ! Alors pourquoi les vendeurs de solutions d’A/B testing ne mettent pas davantage en avant les bonnes pratiques ?
Pourquoi communiquer sur la facilité d'utilisation plutôt que sur la fiabilité des résultats ? Il semblerait qu'il y ait un conflit d’intérêts difficile à résoudre pour eux. D’un côté, ils veulent convertir de plus en plus de clients, et donc faire accepter l’idée qu’on peut facilement faire beaucoup de tests et obtenir des gains de conversions rapides.
De l’autre, la réalité des statistiques fait que pour bien faire un test, il faut que l’échantillon soit d’une taille convenable, et que le test soit exécuté correctement jusqu’à la fin. Ce qui veut dire qu’il peut continuer longtemps après que la signification statistique est atteinte pour la première fois.
Mais les vendeurs ne feront pas l’économie de ce besoin de pédagogie, et ils jouent un jeu dangereux pour leur image en laissant croire à leurs clients potentiels qu'ils peuvent avoir le beurre et l'argent du beurre.
" L’A/B testing n’est pas une baguette magique mais un outil au service d’une stratégie d’optimisation des conversions et doit être accompagné de nombreuses autres disciplines (web analytics, tests utilisateurs, etc.) ", assure Anthony Brebion, responsable marketing d'A/B Tasty
C’est l’analyse en amont qui amène à des tests potentiellement intéressants. Les agences de conseil ont un rôle prépondérant à jouer à ce titre pour former les utilisateurs de solutions d’A/B testing à l’optimisation des conversions au sens large. Les utilisateurs finaux doivent aussi développer une expertise dans ces domaines.
Autrement dit, pour l'instant, mieux vaut se faire aider et surtout se plonger dans ce sujet pour être au top avec un outil qui, s'il est de plus en plus indispensable, peut aussi être à double tranchant.



